
Why has Autonomous Driving failed? Perspectives from Peru and insights from NeuroAI
Modern Autonomous Driving systems that are being developed in 1st world countries such as in the United States of America (USA), United Kingdom (UK) and China are currently being released on the streets to test their levels of autonomy. Perhaps not to the surprise of many computer vision scientists (despite the outstanding progress in Computer Vision), these systems have not been operating at the level they initially hoped they could be in production a.k.a. The Real World.
Since 2022, many self-driving car companies have gone bankrupt, and even larger companies that have been funded with billions of dollars such as Waymo, Tesla and Cruise are now down-sizing their teams and still struggling to keep the self-driving car dream alive. And while yes, there have been many breakthroughs in machine vision to date -- why do these accidents still occur? And why do machines behave differently than humans on the driving wheel?
We think that the perceptual failure of autonomous driving are occurring due to two main reasons: 1) lack of perceptual understanding of out-of-distribution stimuli, and 2) lack of high-quality benchmarks for such out-of-distribution scenarios. In many cases, self-driving cars are being trained with real or synthetic data (see Parallel Domain) on near perfect sunny or uncrowded conditions with perfectly working traffic lights, well-paved roads, and law abiding drivers and mindful pedestrians. However, when the chips are low and cars must navigate through foggy weather, a crowd in a parade, dogs running (or playing) in the street without a leash, or checking for scooters along the side lanes -- perceptual inference on many of these systems start to second-guess.
Our hope is that by testing systems on such adversarial conditions and providing such qualitative benchmarks, we will be able to make progress in the development of perceptual inference for self-driving cars in both developed & developing countries. If an autonomous vehicle can easily navigate & identify every object and obstacle from routing videos in Lima, Hanoi or Bombay, then making perceptual inference in cities like San Francisco, London and Beijing should be trivial. Moreover, we’d suggest that training computer vision systems of Autonomous Driving vehicles should be done outside of the city of focus/deployment. In machine learning this is commonly known as Adversarial Training -- where by training systems in adverse and heavily out-of-distribution stimuli, neural network representations have a higher chance of performing better when faced with both the expected & the unexpected, in addition to being closer to learn brain-aligned representations as research at Artificio (Berrios & Deza. SVRHM 2022) and MIT (Harrington & Deza. ICLR 2022),Feather et al. (Nature Neuroscience 2023) suggests.
Given these two observations, in this blog post we propose two solutions that may help keep the Autonomous Driving dream alive : 1) Collect more out-of-distribution datasets from developing countries where these type of out-of-distribution driving patterns are more common (such as Lima, Peru) to benchmark (and train) the autonomous driving system’s computer vision on these datasets; and 2) Shift the training paradigm of such computer vision systems from big data to representational alignment (NeuroAI) -- because Scale is Not all you Need.
Initiating our Journey: An Overview of Our Work
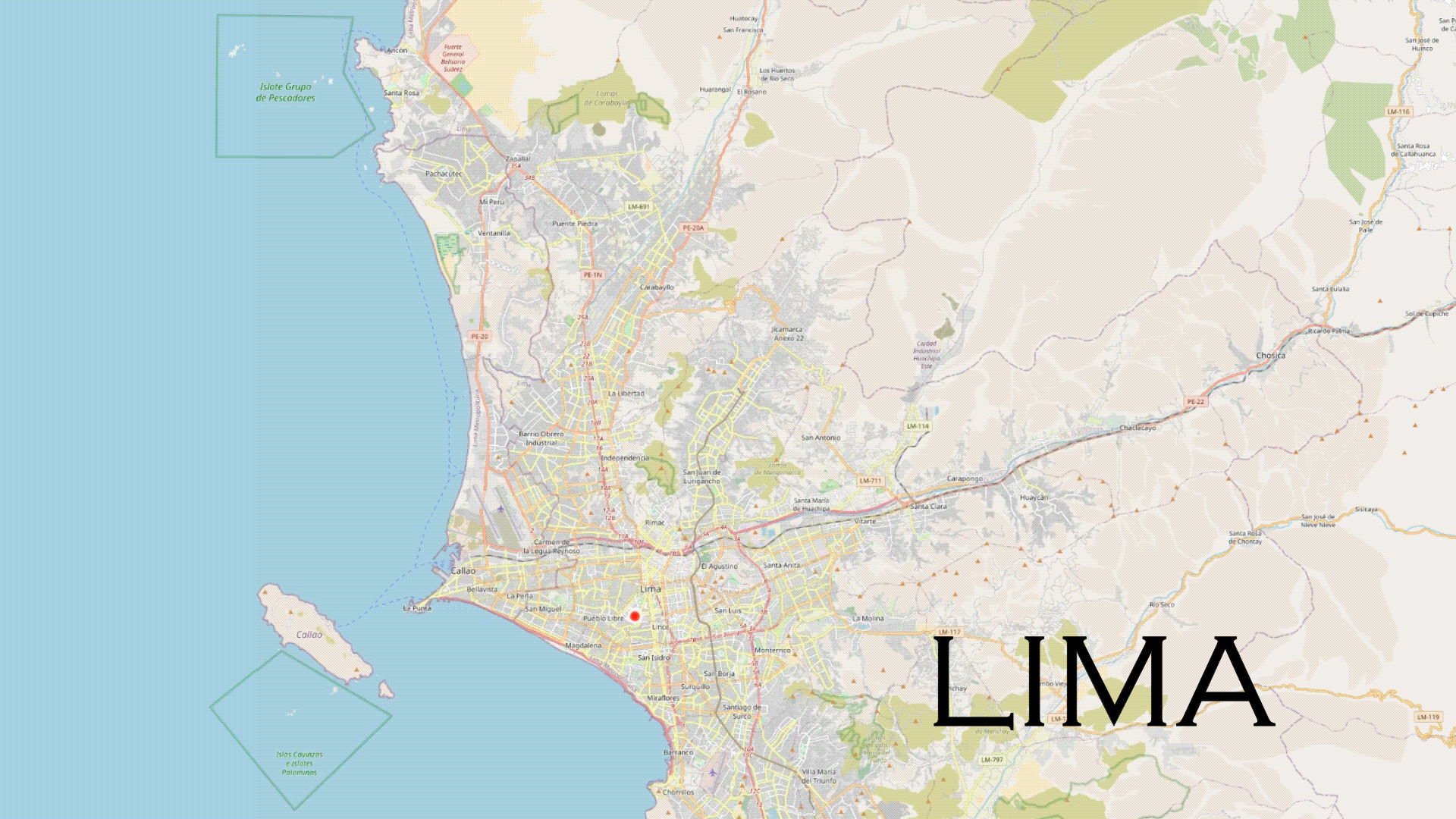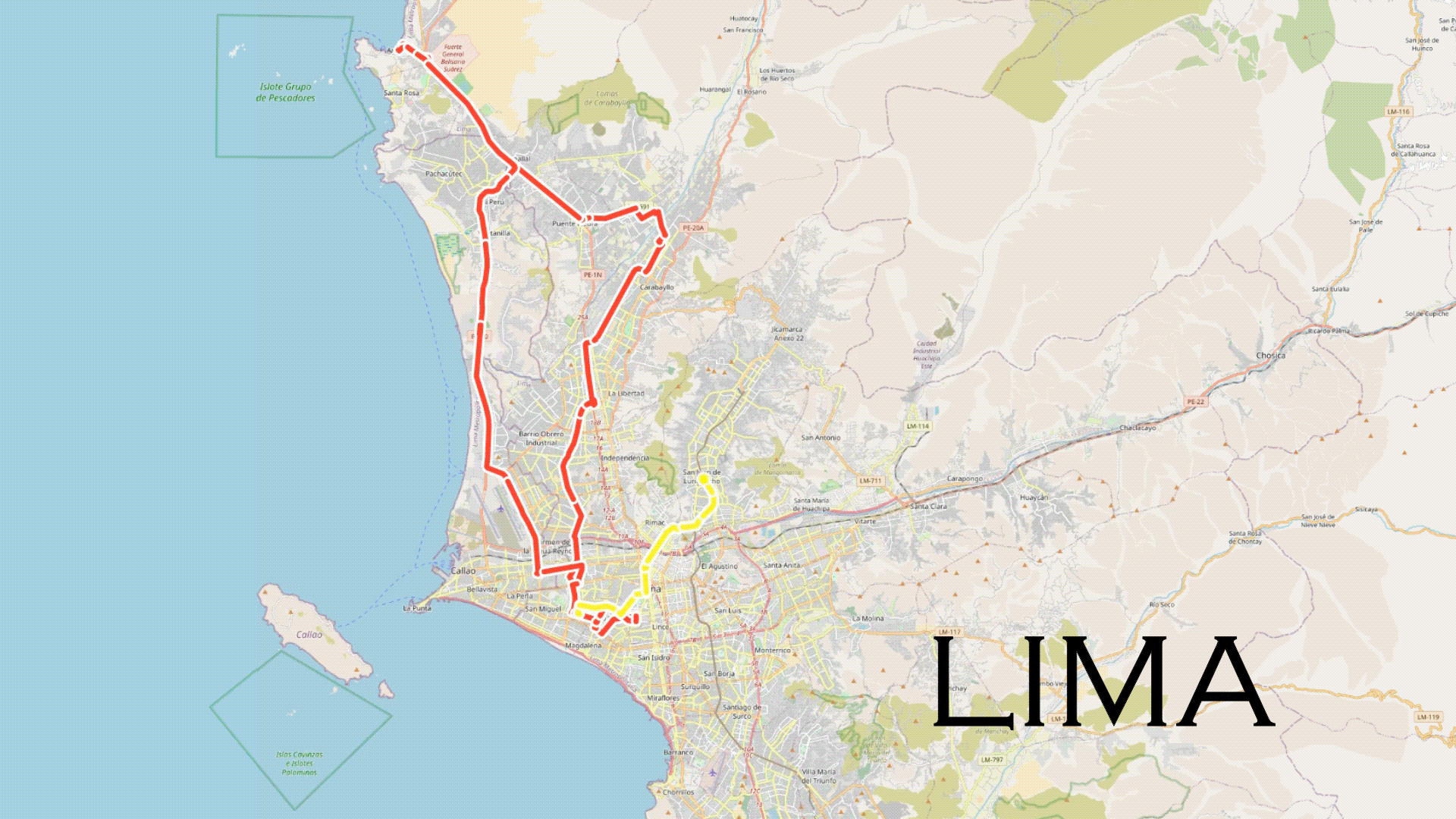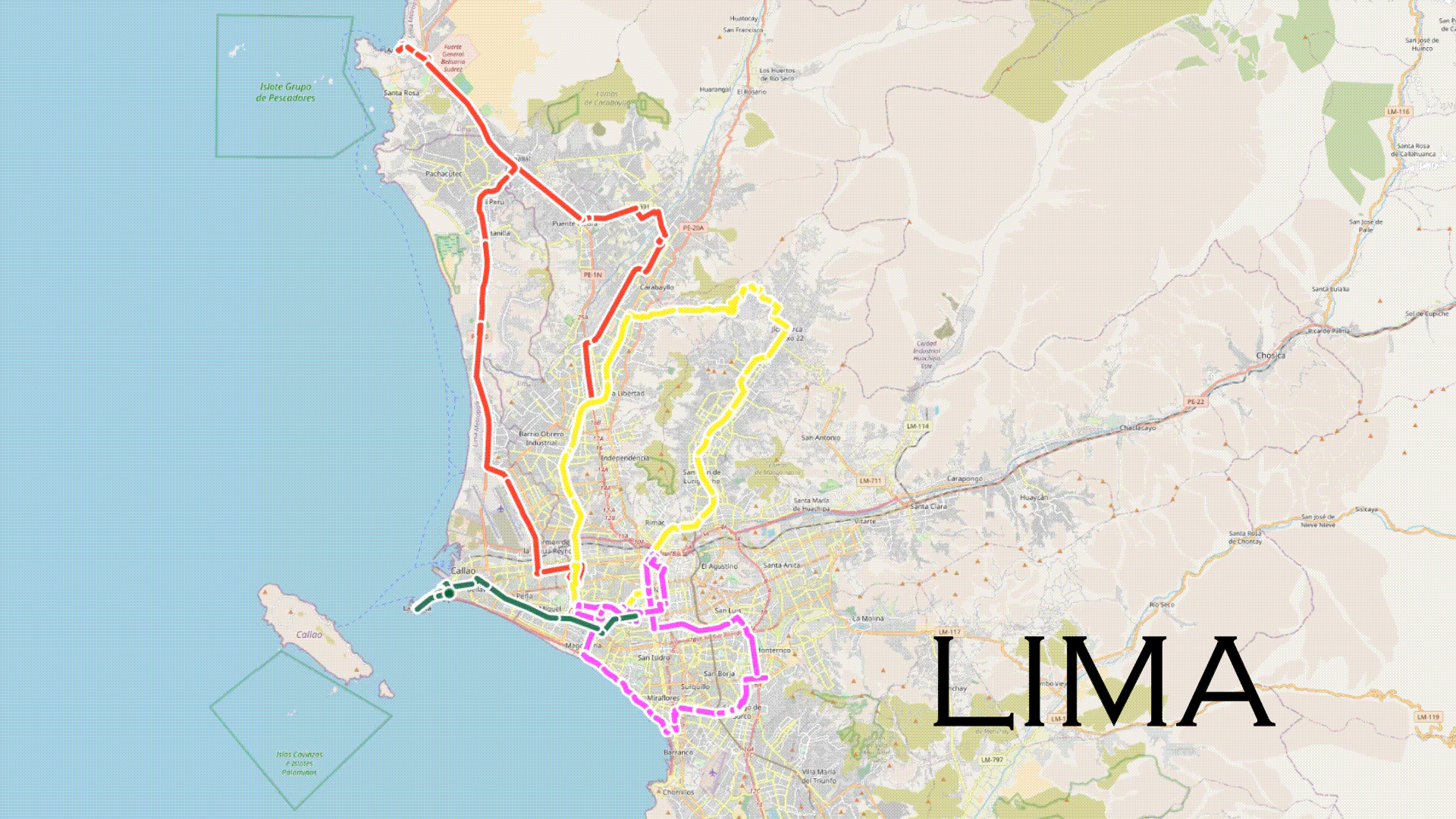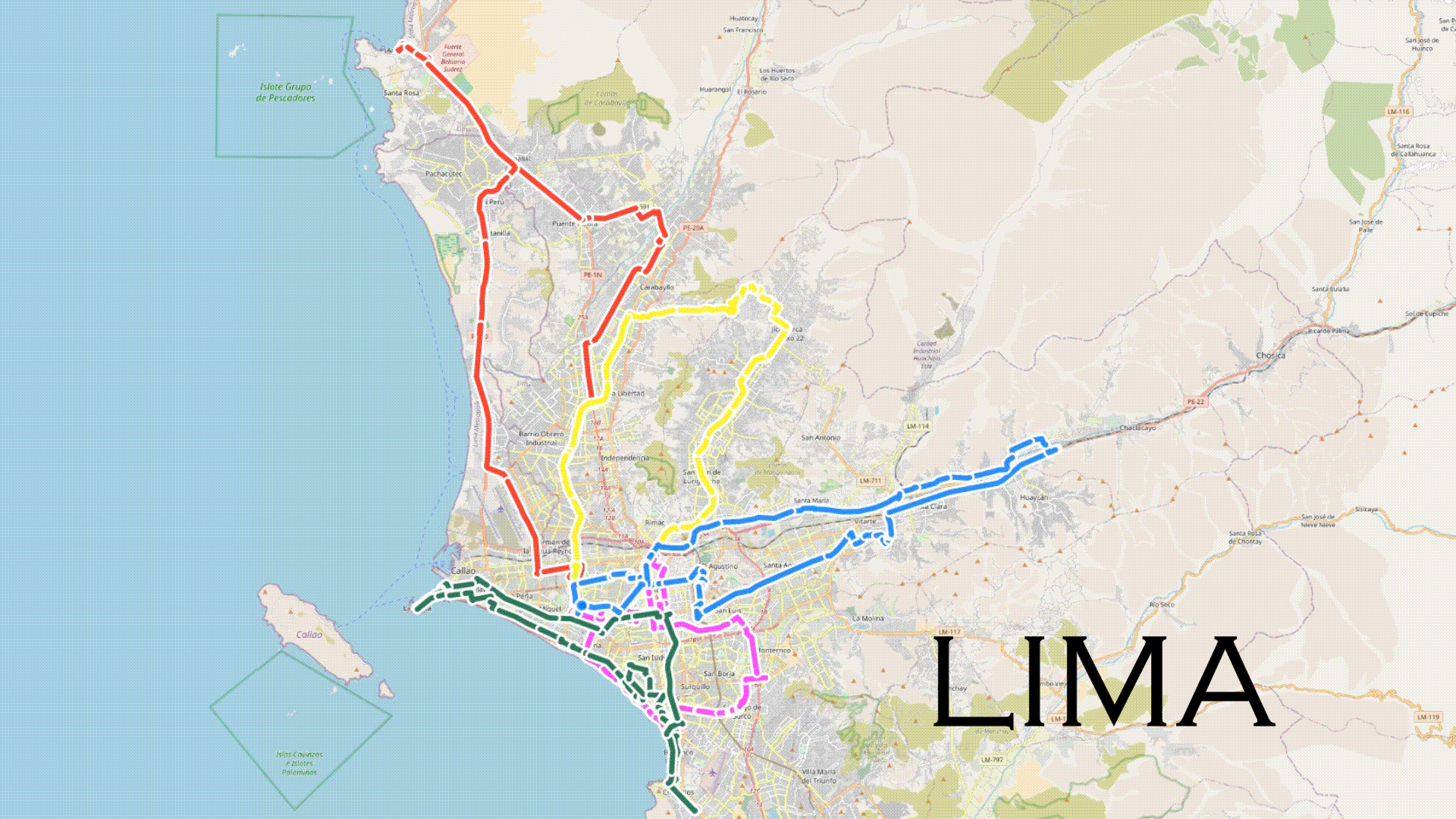
.gif)
Around December of 2022 (1 year ago) , we decided to embrace multiple journeys across various cities in Latin America to collect videos that would later serve the purpose of testing the performance of existing computer vision models, such as YOLO. Given the initial location of the working team, our journey began in Peru.
The decision was made to collect data from the cities of Lima, Cusco, and Cajamarca due to the ease of travel to Cusco and Cajamarca and the team's primary location in Lima. Lima, in particular, with its vehicular and cultural diversity, offered a unique and interesting data collection opportunity. The journey began in the city of Cusco between December and January. Consequently, the data collection includes itinerant fairs and a massive flow of people in some parts of the city. The weather conditions varied from sunny days to days with rain and hail. On the other hand, the journey in Lima required a different planning approach due to the city's impressive variety in vehicles, driving behavior, and traffic congestion. In total, 22 districts out of the 43 in Lima were covered, and the collected data in this city could pose a real challenge for any computer vision model. Finally, the journey in Cajamarca included both rural and urban content, with a variety of vehicles and consistently sunny weather conditions.
As data collection progressed from December 2022 to February 2023, behavioral patterns & variations from pedestrians and drivers, as well as a diversity of vehicles based on the city, became evident. The collected data includes information from both rural and urban environments. According to TomTom Traffic, Lima is the city with the worst traffic in South America. For this reason, data collection was performed during the same time window (2 pm - 6 pm) to avoid traffic congestion. 6pm being the highest peak of traffic in Lima, similar to many other cities in the world (1 hour after the end of the working day).
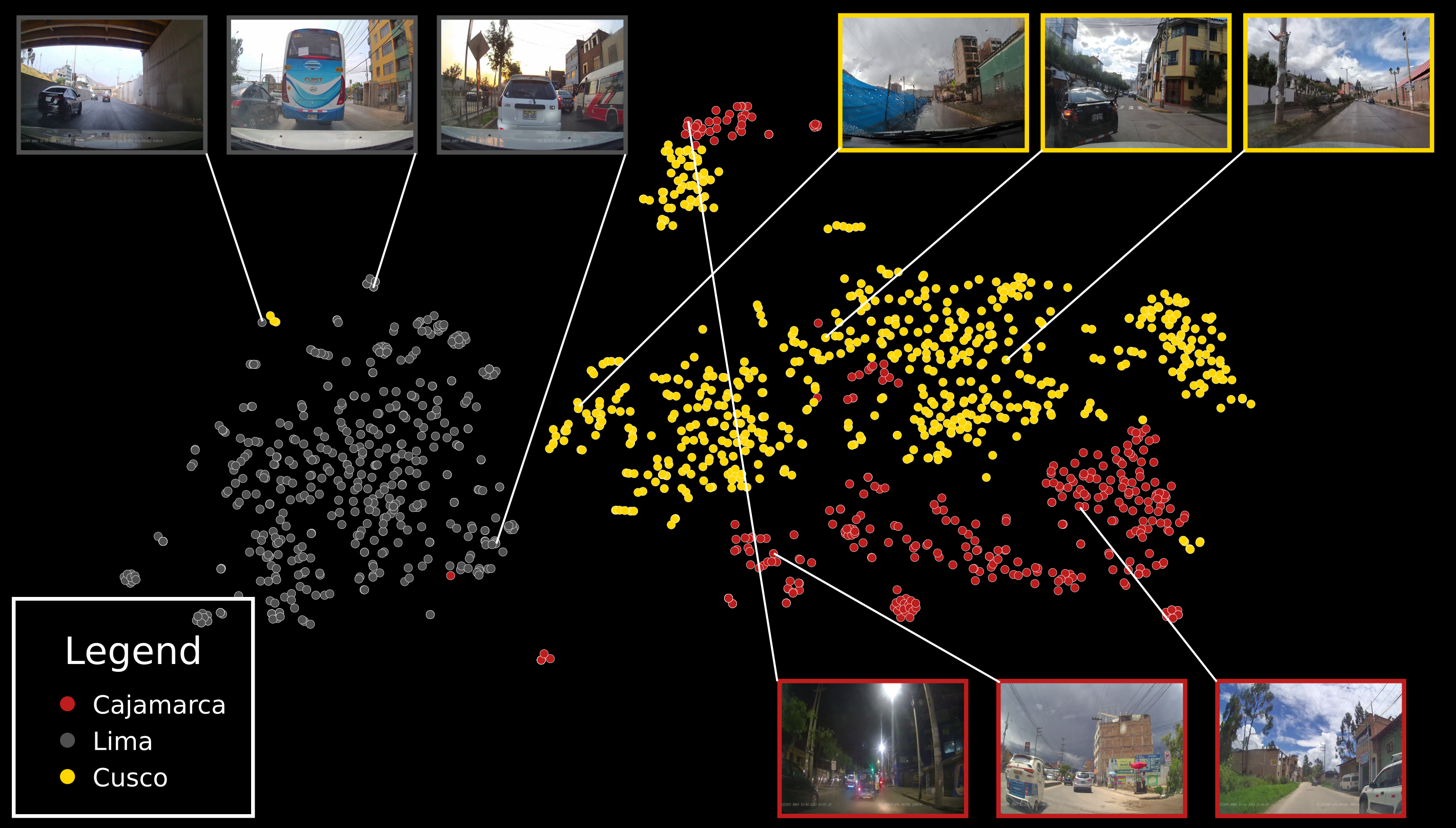
lasted on average between 5 to 7 minutes.
Data Collection Devices
To initiate data collection, the use of a camera placed beneath the rearview mirror was considered to visualize the road. Therefore, the camera needed to be lightweight and compact, leading to the consideration of dashcam-type cameras. It is worth emphasizing that our initial idea was to test how well the models performed in typical traffic environments and gradually incorporate more cameras and sensors based on those results. Artificio's future goal is to implement various cameras and sensors, such as AEVA’s LIDAR, in a vehicle, as different models work with different types of input information. By collecting this data, we will be able to test and benchmark a suite of computer vision systems on rare objects and different street-view distributions in LATAM. We started with the Comma Three, but ended up switching to dashcam’s instead as noted below.
A device designed to be permanently installed in your car, the Comma Three was created to run Openpilot. It features 3 HDR cameras: 2 cameras for road visualization and one night vision camera for interior observation. In addition to cameras, the Comma Three has connectivity and sensors like LTE, Wi-Fi, IMU, high-precision GPS, and microphones. Our initial plan was to use this device to test Openpilot in accompanied, chaotic, and disorderly environments to identify flaws and establish benchmarks but after testing it, we encountered the following issues: as the device operates directly with openpilot, which starts its recognition when it receives CAN signals from the car, we could not manage to run Openpilot because the vehicles we had access to were not compatible, as they mention on their website.
On the other hand, it was possible to use the comma three as a dashcam; however, certain configurations were required, such as using an external toolkit to record and store information without sharing it. This led us to use more hardware (such as a PC) and, moreover, conduct tests that took longer than expected. Finally, the decision was made to look for a dashcam that has similar features to the cameras used by the comma three. The cameras used are listed below, along with their technical specifications.

The problem: Out-of-Distribution Objects & Labeling
After the data was collected, the next natural step was video labeling to subsequently establish benchmarks and assess the performance of available open-source models. In addition, labels are needed to perform supervised learning on top of new datasets and we are in the process of training our own self-supervised models on this data to create robust embeddings for out-of-distribution autonomous driving redundancy checks. Indeed, during the labeling process, certain issues arose -- mainly those around object identity -- that were not straightforward to define without some form of consensus, as they could be perceived differently by different individuals. These issues are outlined below:
Types of Obstacles
Different types of obstacles are more frequently encountered on rural routes due to infrequent road condition checks by authorities. In our experience, we have identified two types of obstacles: those that must be avoided (Avoiding Obstacles) and those that are part of the road (Non-Avoiding Obstacles), such as improvised speed bumps, gutters, etc. A more detailed description follows:

Motorized and Non-Motorized Vehicles
In Lima, Cusco and Cajamarca, there were a wide variety of encountered vehicles that needed a better way of discriminating between their classes. In addition to conventional vehicles such as buses, cars, motorcycles, etc... There were also unconventional vehicles such as Tuk-tuks, ice cream carts, motorcycles with front baskets, etc. Some were motorized, while others were not, making this classification necessary for subsequent models to be aware of what is on the road [mainly meta-awareness of their speed], given the different behavior of motorized and non-motorized vehicles in terms of actions and states they can have in the environment.

Qualitatively Benchmarking Computer Vision Systems on the Artificio-PER dataset
Stumped by not knowing how to proceed and exhaustively label all the data, we turned to performing a qualitative assessment of many of the computer vision models that are popular today and may act as an approximation (hopefully a lower bound) of current self-driving car perception technology.
We deployed YOLO-V8, EVA-01 and Detectron2 on the data collected from the cities of Lima, Cajamara and Cusco and arrived to the following qualitative conclusions :
- In most cases, these computer vision systems have no problems in correctly finding a pedestrian (very little risk for false negatives). We are working on fully labeling our dataset to perform a more precise calculation of both false negative and false positive pedestrian detection and classification.
- There seems to be a high risk of false positives and confusion however between cars, buses and trains. Perhaps this is not a “problem” because at the end of the day they are all moving obstacles, but in some cases we found bizarre examples such as a wall being misclassified as a train. Many of these mistakes can be seen in the video of the last section.
- Not all models agree on what the detections and classifications should be, potentially suggesting an ensemble model would help current AV technologies.
NeuroAI: Brain-Alignment & Similarity Search as a Fail-Safe Mechanism for Autonomous Driving
As a tentative solution to solve the problem of object classification we proposed a similarity search mechanism to find similar looking objects without labeling the input stimuli and by extracting geometrical properties from the images. This is also known as using a visual embedding for image retrieval and search, and is popular in many e-commerce search engine platforms where users want to buy “a similar object” -- Google Lens being the most well known visual search engine feature at a web-scale, or “similar paintings” (see our very own Seezlo Engine that was not trained on Art, and yet works exceptionally well to retrieve similar art pieces over a local dataset).
Back to Self-Driving Cars: how and why should modern perceptual systems in autonomous vehicles then use this type of technology? We propose a retrieval-based approach where vehicles may query any random object from their visual pipeline and find the most similar object that has previously been classified to potentially resolve this conflict.
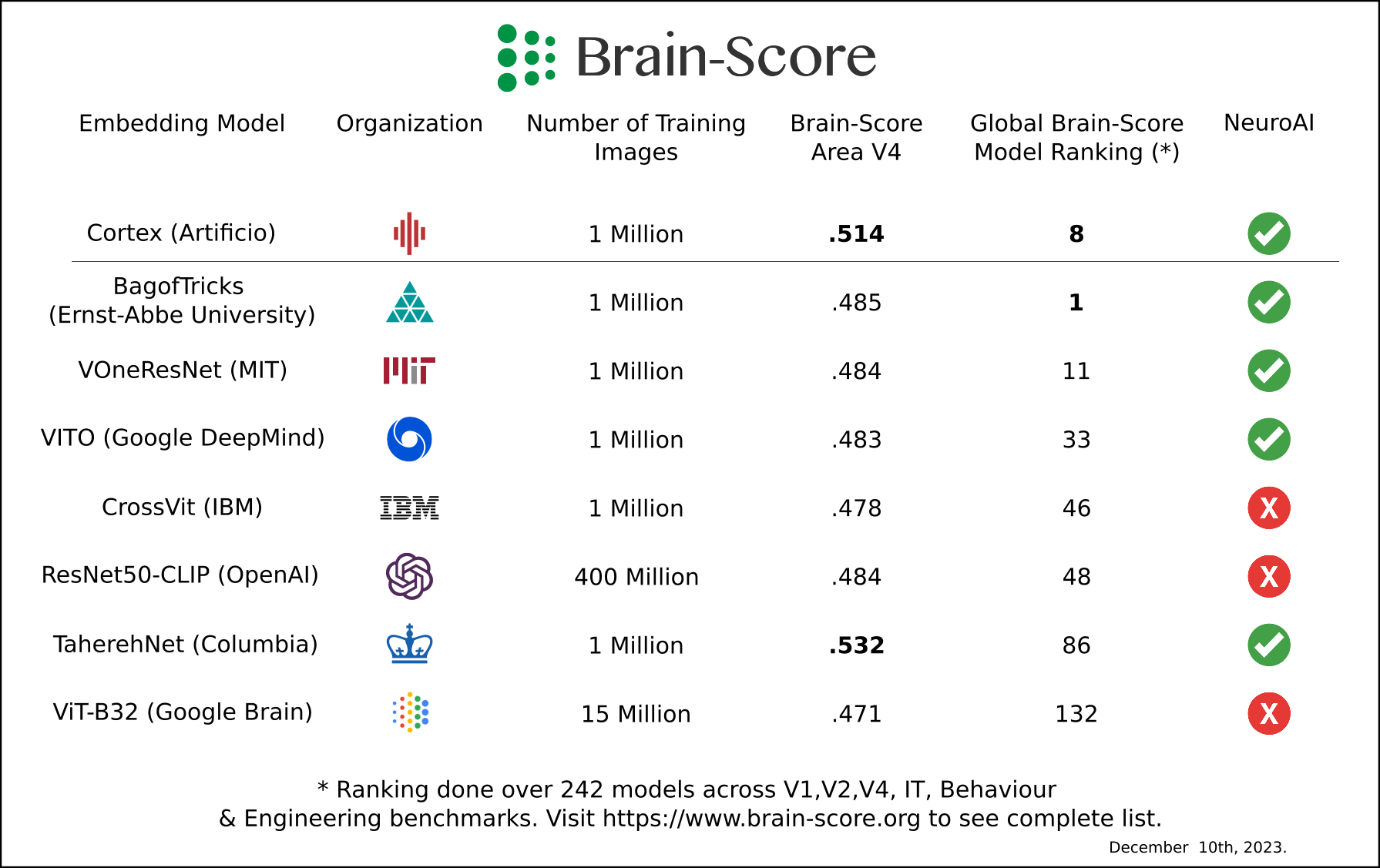
Below we show and benchmark how several visual embeddings ranging from OpenAI ResNet-CLIP & ViT-CLIP (trained on 400M images), Artificio Cortex (trained on 1M images) can perform some of these tasks for several objects that look “tricky” for humans & machines. Notice mainly that models based on NeuroAI technology (that seek to optimize for brain-alignment rather than performance on object recognition as done in deep learning), are more robust in this task and are also not data hungry.
To push this point further, there has been a recent wave of NeuroAI models that the Deep Learning community has largely been unaware of that have been changing the playing field in terms of perceptual alignment with humans, because these models do not require millions of training images, nor a GPU farm, nor a large sum of investment money to train on. We believe that in 1-2 years time, this miniaturization effect that is being driven mainly by neuroscience labs (and start-ups like Artificio) will catch-up globally to other big players in AI by 2025.
Want to read more about NeuroAI and representational alignment -- a movement that is taking this year’s NeurIPS [2023] by storm? Check out this epic paper by Sucholutsky, Muttenthaler et al. 2023 and the works published at CCN & SVRHM (a NeurIPS workshop) from 2019 to 2022.
Analogous to many modern leaderboards for LLMs, the Brain-Score organization based at MIT’s Quest for Intelligence and MIT's Center for Brains, Minds and Machines, has one of the world’s largest benchmarking platforms for current computer vision models where these models are correlated to actual primate neural data. Our foundational model Cortex, was ranked world #1 last year for predicting activation of visual area V4, and is currently #8 globally out of 242 models. It cost us no more than $15’000 to train this model, and it is safe to say that the same applies for many other NeuroAI models in this table that come from academic labs and research groups where the scientific team is a mixture of Computational Neuroscientists and AI experts.
But what *is* the advantage of Brain-Aligned models, and why should the Self-Driving car community care? Remember Adversarial Images? Those micro-distortions that are optimized to fool a neural network in the most bizarre way? Brain-Aligned models do not suffer from these types of stimuli -- or rather they do -- but when they are attacked, the adversarial stimuli that emerges fool humans as well and no longer looks like noise, making the adversarial image interpretable and giving a strong signal of perceptual alignment with humans. Some example of how NeuroAI models (and our very own Cortex) behave:
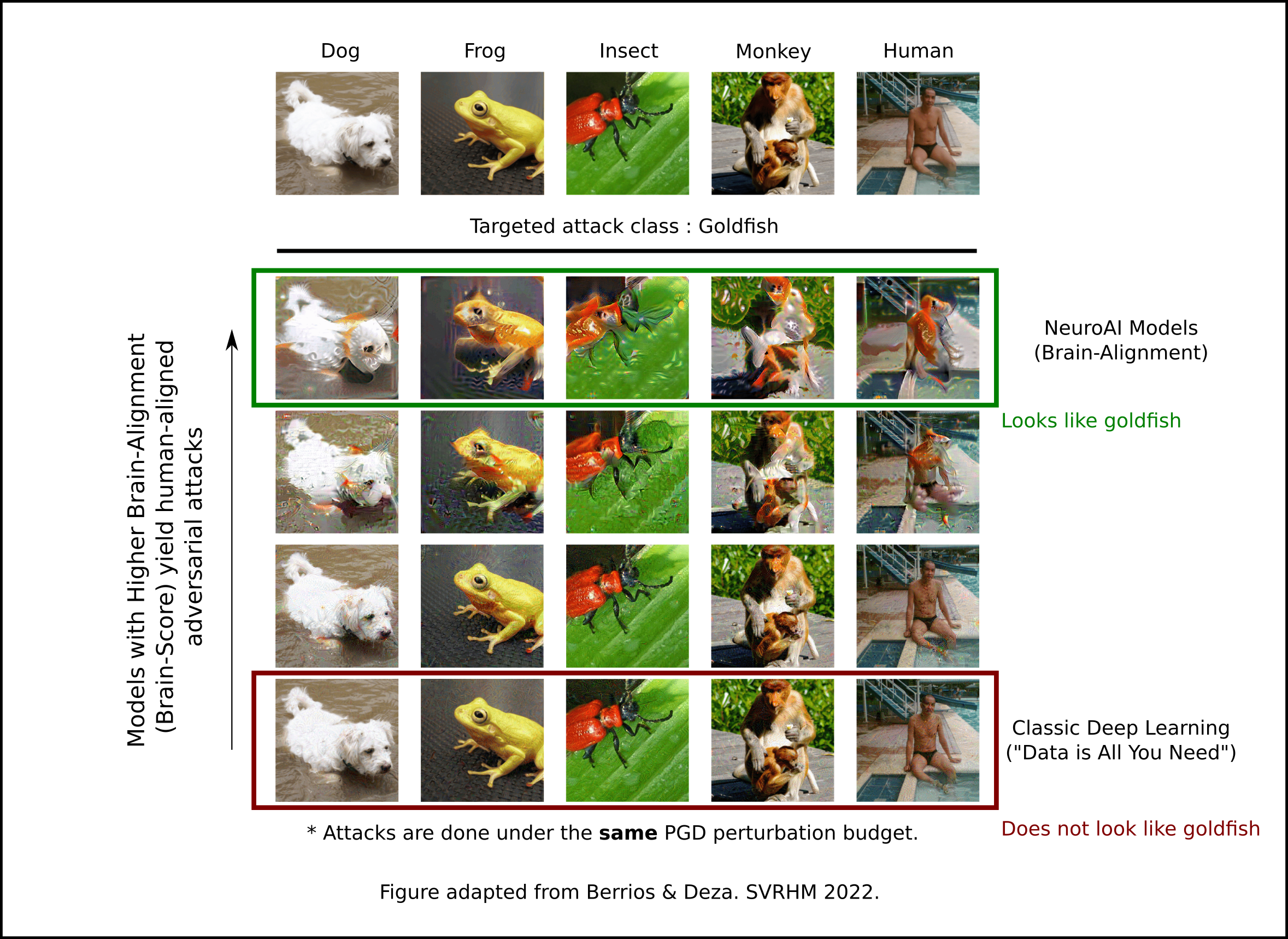
One can now imagine a future where self-driving cars have NeuroAI models as part of their perceptual inference engine because it allows them to make *reasonable* and *interpretable* errors. As legislation around self-driving cars progresses, and society's own complexities evolve, self-driving cars should be able to perceive and reason the same way humans do (because yes, even Multi-Modal LLMs make these mistakes, so neither multi-modality or big data will be the final answer).

Final thoughts: Out-of-distribution data is a feature not a bug, and could potentially solve Autonomous Driving if coupled with NeuroAI models.
It is to our best of knowledge that self-driving car companies do not employ these techniques or scientific approach, and the culprit for accidents could be due to over-fitting on a particular city by training (heavily) and testing on the same distribution -- without challenging the network strongly enough at training thus failing at testing when shown unexpected imagery. This, compounded by the effect that many self-driving car companies are betting that more data pools of identically distributed data (i.i.d.) will solve the problem -- an idea that as argued above may not be the case -- seems to make the Self-Driving car market lead to a crash unless they re-evaluate their approaches.
A similar set of ideas was also once explored by a 2015 founded, but now closed Series B start-up Perceptive Automata as Self-Driving Car companies did not seem to think this was a problem until now -- when C-suite executives are resigning from their roles given the hardship that self-driving cars are facing in the market, and the empirical evidence that these systems still do not understand their environment when pushed to the limit (which is exactly when accidents occur).
The moral of the story, with an ironic touch of caution from Perceived Automata to many other Self-Driving car companies, suggests that established companies should consider partnering with startups and academic labs rather than underestimating them, looking into the future to solve this challenging problem together. If there is any way we can help, we are happy to collaborate with academic and industrial partners in this endeavor.
We are looking forward to releasing this dataset, bench-marking results and annotations too for scientific and commercial purposes soon. Stay tuned & write to us if you would like to learn more. And don’t forget to follow-us on X for more updates
Sincerely,
The Artificio Team
Lima, Peru. December 2023.
Core Contributors:
Lead Research Scientists: Dunant Cusipuma & David Ortega
Supporting Research Scientist: Victor Flores
Research Director: Arturo Deza
If you have found this post relevant for your research please cite as:
@misc{Ortega_Cusipuma_Flores_Deza_2023,
title={Why has autonomous driving failed? perspectives from Peru and insights from neuroai},
url={https://www.artificio.org/blog/why-has-autonomous-driving-failed-perspectives-from-peru-and-insights-from-neuroai},
journal={Online Blog Series},
publisher={Artificio Blog},
author={Ortega, David and Cusipuma, Dunant and Flores, Victor and Deza, Arturo},
year={2023}}
